MLOps Is Not a Tool. It Is a Mindset. And Most Companies Are Getting It Wrong.
Here is a frustrating truth that the machine learning industry took years to admit publicly: most ML models never make it to production. Surveys put the number at somewhere between 70 and 90 percent of models trained in enterprise data science teams that never get deployed. They sit in notebooks, validated on test sets, celebrated in internal presentations, and then quietly abandoned when the engineering and operations work of actually shipping them turns out to be harder than anyone budgeted for.
MLOps exists to fix that. But the way most organizations approach it guarantees they will still get it wrong.
In 2026, enterprises are no longer asking "Can we build ML models?" They are asking "How do we deploy, scale, monitor, and govern ML models reliably in production?" This is where MLOps becomes critical. The bottleneck has shifted. Building ML models is no longer the hard part. Running them reliably in production is. Kernshell
That shift in the central question is everything. When the hard problem was building capable models, organizations hired data scientists. Now that capable models can be bought, borrowed, or fine-tuned, the hard problem is operational. And the skills required to solve operational problems are not the skills that most data science teams were hired to have.
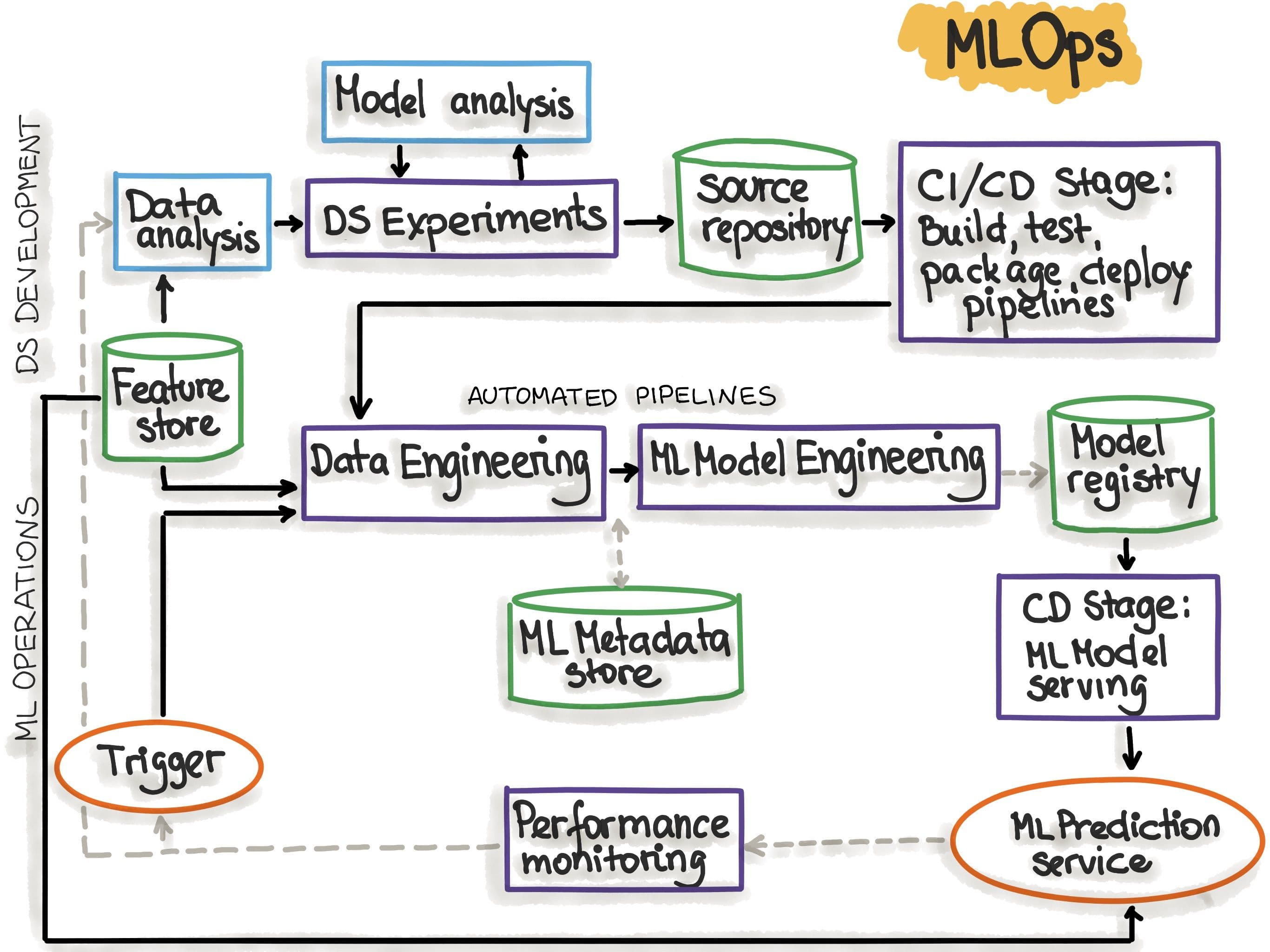
What MLOps Actually Is
Machine learning operations are a set of practices that automate and simplify machine learning workflows and deployments. MLOps is an ML culture and practice that unifies ML application development with ML system deployment and operations. Your organization can use MLOps to automate and standardize processes across the ML lifecycle, including model development, testing, integration, release, and infrastructure management. AWS
The word "culture" in that definition matters more than any of the tools. Organizations that implement MLOps as a tool procurement exercise, buying platforms and setting up dashboards without changing how teams work and who owns what, get the costs of MLOps without the benefits. The tools are not the transformation. The operating model is.
Machine learning initiatives rarely fail because of model quality alone. They fail because data pipelines break, deployments are fragile, monitoring is missing, security is weak, and ownership is unclear. Walk through any post-mortem of a failed enterprise AI project and you will find one or more of those root causes. The model was fine. Everything around the model was the problem. Medium
The AWS Approach to MLOps Maturity
AWS has published guidance on what they call the MLOps maturity journey, and it is a useful framework regardless of whether you use AWS tools. The maturity journey consists of four stages: Initial, where you establish the experimentation account; Repeatable, where you standardize code repositories and adopt a multi-account implementation approach; Reliable, where you introduce testing, deployment, and multi-account deployment; and Scalable, where you templatize and productionize multiple ML solutions across multiple teams and use cases. AWS
The value of this framework is its honesty about sequence. Most organizations try to jump to Scalable before they have achieved Repeatable. They want automated retraining pipelines and model monitoring dashboards before they have established the discipline of version controlling their data and code. The result is automation built on an unstable foundation, and automated instability is worse than manual instability because it fails faster and more creatively.
On AWS, the core tooling for each stage centers on SageMaker. SageMaker Pipelines is a purpose-built CI/CD service for machine learning. It brings CI/CD practices to ML, such as maintaining parity between development and production environments, version control, on-demand testing, and end-to-end automation, helping scale ML throughout the organization. AWS
The Monitoring Problem Nobody Budgets For
Production model monitoring is where most MLOps implementations have their largest gap. Organizations spend months building training pipelines and deployment infrastructure, get the model into production, and then allocate approximately zero engineering capacity to watching what happens next.
Data drift occurs when the statistical distribution of real-world input data changes from the data the model was originally trained on. Without MLOps, organizations face fragile deployments, unpredictable model behavior, and rising operational costs. Kernshell
A fraud detection model trained on pre-pandemic transaction data will perform differently in 2026. A recommendation model trained before a competitor launched a new product category will start making increasingly irrelevant suggestions. A demand forecasting model that does not account for a new seasonal pattern will produce systematically wrong predictions in silence. These failures are not dramatic. There is no error message, no crash, no alert. The model just quietly becomes wrong while the business continues to act on its outputs.
Best practices for MLOps include versioning all code, data, and models; implementing CI/CD automation; monitoring models for performance and data drift; ensuring governance and compliance; enabling full reproducibility; defining infrastructure as code; planning for continuous retraining; and fostering cross-team collaboration. Azilen Technologies
Continuous retraining is the part that sounds easy and is operationally complex. Retraining requires fresh labeled data, which requires a labeling pipeline. It requires an evaluation framework to determine whether the new model is actually better than the old one on real production traffic, not just on a static test set. It requires a deployment mechanism that can roll out the new model safely, with the ability to roll back if something goes wrong. None of that is hard individually, but assembling it reliably and maintaining it across dozens of models simultaneously is a serious engineering challenge.
The Team Structure Question
Successful MLOps requires a clear operating model with defined roles: Platform and DevOps engineers for infrastructure, tooling, and platform maintenance; Data Engineers for data pipelines, quality, and governance; ML Engineers for productionization, deployment, and monitoring; Data Scientists for experimentation and model development; and Business Owners for per-model SLAs, success metrics, and prioritization. Medium
Organizations that collapse these roles, that expect a data scientist to also own the deployment pipeline and the monitoring infrastructure and the data engineering, produce burnout and brittle systems. The disciplines are genuinely different. A data scientist optimizing model architecture thinks completely differently from an infrastructure engineer designing for fault tolerance at scale. Both skills are necessary. They are rarely found in the same person.
What Good Looks Like
MLOps will become the operating system for enterprise AI. In 2026, machine learning success is not defined by model accuracy. It is defined by reliability, scalability, governance, and business impact. Kernshell
A mature MLOps implementation means a new model can go from a data scientist's notebook to a production endpoint with appropriate testing, review, and governance in days rather than months. It means that when a model's performance degrades, the right person finds out before the business does. It means that when a regulator asks what data trained a particular model that made a particular decision, there is a clean, auditable answer within hours.
Those outcomes are not glamorous. They do not generate conference talks. But they are what separates organizations that use AI as a strategic asset from organizations that use it as an expensive science experiment. The tools to build this exist on AWS today. The harder work is building the culture, the team structure, and the operational discipline to use them effectively. That part does not come in a service catalog.